
The ‘how’ of data governance: increasing data security, privacy and compliance
Data governance is as broad a topic as data itself, and as such, there are far too many of these ‘how’s’ to cover in one article. This article is the third, and final, part in a series to go over many of the desk level procedures that make up data governance. For more information on this topic, read part one, The 'how' of data governance and part two, Implementing data quality initiatives.
Data governance is being talked about more and more in the industry, and organizations are realizing the need to build process and controls around their data assets. However, a lot of this talk does not detail what actionable steps can be taken as part of a data governance program. The purpose of this article series is to lay out pragmatic steps organizations can take to build out their data governance program. Parts one and two of this article series covered documenting data assets to increase data literacy at your organization and how to enact data quality initiatives. This article will examine one of the primary reasons organizations implement data governance programs – which is to increase data security, privacy, and regulatory compliance.
Managing the data lifecycle
The volume, variety, and velocity of data organizations are storing is growing exponentially. Without a system in place to manage this data, it can be difficult for organizations to scale with this growth. As a result, the quality of data assets declines as maintenance costs increase. It is likely that as much of 90% of the data organizations store is not even being analyzed (1). Additionally, classified and sensitive data can pose a liability threat to organizations storing them.
It is critical that data governance programs define systems for managing the lifecycle of their data. Depending on the industry, government regulations and legal requirements – knowing the proper way to manage each piece of data can be overwhelming for data engineers. Governance programs should appoint compliance officers from business and legal departments. These individuals should be experts in regulations and can advise the data team on the necessary procedures. There are five stages that make up data’s lifecycle: ingestion, storage, usage, archival, and disposal. For each of these, the data team should work collaboratively with compliance officers to determine appropriate safeguards and procedures.

- Ingestion: Consider whether each piece of information is necessary to pull into your data platform, especially if it is sensitive. Every piece of data represents a liability risk and a maintenance cost so if the business does not benefit from having it, the data team should not add it to the system.
- Storage: Data stewards should work to classify the data elements which are available to the business. Data which is classified (legally cannot be made public), sensitive (would be embarrassing if made public), or tied to specific regulations (Protected Health Information or Protected Personal Information) should be tagged in the data catalog as such.
- Usage: Define how the data can be accessed, by whom, and who on the business side is the data domain owner to grant this access.
- Archival: For many data assets, there is a set time frame between when data is regularly used and when it can be disposed of. This may include audit and legal data archived according to specific regulations. Evaluate which of your data assets fall into this stage, as there may be more cost-effective data storage options.
- Disposal: At a certain point, the cost of maintaining data eclipses its value to the organization, especially if that data is outdated or inaccurate. Establish a regular process for your governance team to audit data assets to determine if any fall into this stage.
Data lineage
Due to increasing concerns around data privacy and regulations such as General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA), it is essential for organizations to understand what data they have, where it is stored, and where it is used. This cannot just live in the brains of developers in information management. A function of data governance is to help make this information accessible and understandable to all business users touching the data.
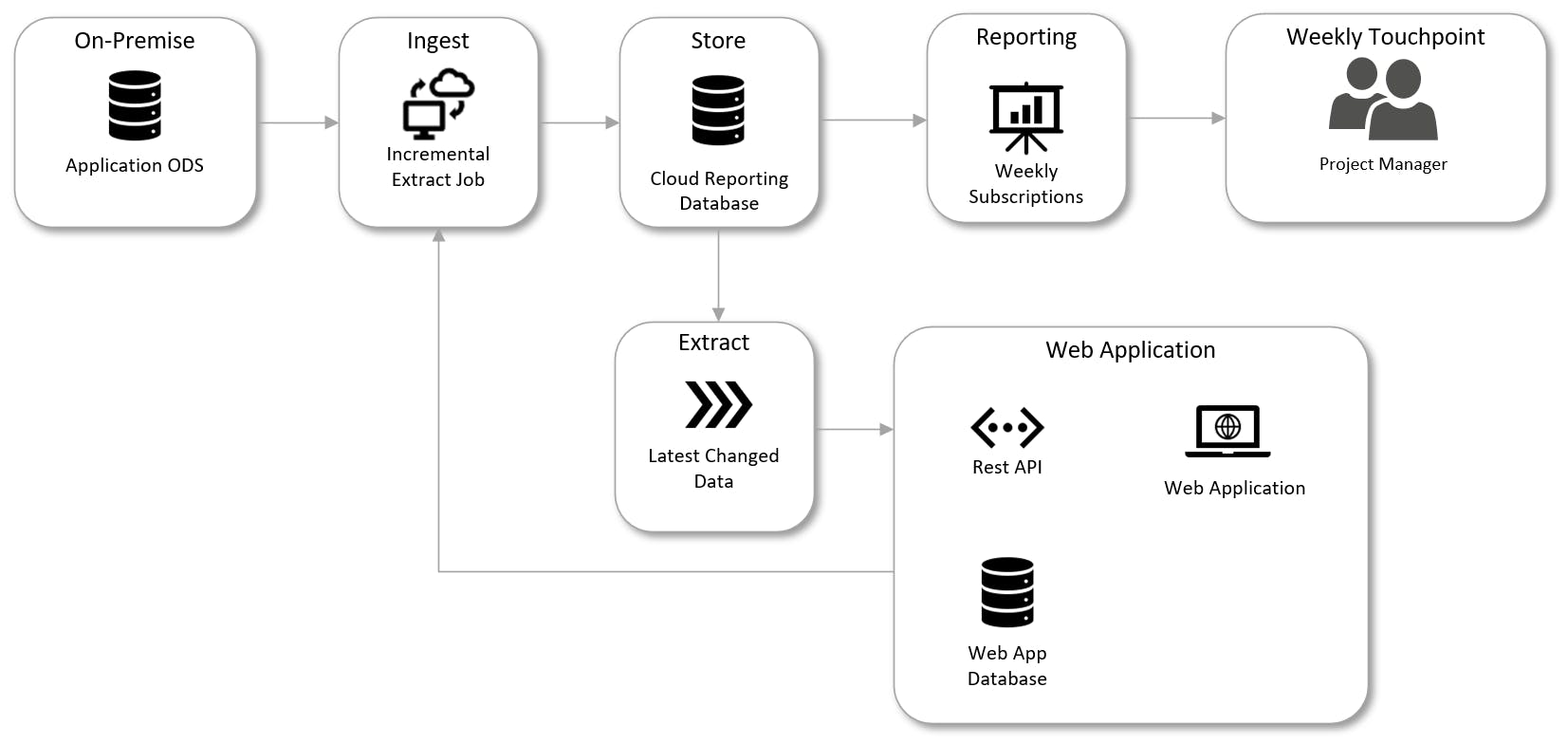
The first step to understanding this is building out a Systems of Reference map. This can be as simple as a flowchart which diagrams organization source data, processing tools and analytics outputs that make up your data platform. This should be a central source of documentation used frequently by the data team and business users. Showing the lineage of data clearly shows all the aspects of the platform that are impacted by each data domain.
Example of a Systems of Reference map
Access and controls
Unfortunately, data breaches are becoming more and more common in the industry. The number of data breaches in 2020 almost doubled the amount that took place in 2019 (2). Although a big part of this rests with the information security team, data governance is an important component. The role of data governance is ensuring that data is not only safe, but also accessible across the organization in a controlled manner. This is a dual effort between information management, typically database administrators and data domain owners.
Part one of this series highlighted the importance of a data catalog to inventory the data assets an organization stores. Within this catalog, a data domain owner should be assigned to each asset. This data domain owner should determine how this asset should be used and who should be granted access. In some cases, the data domain owner would be able to grant access themselves. If this role needs to be done by information management, data governance should also document this in the catalog to make it easy for users to be granted access.
To keep access simple, define a handful of access roles. Roles can be configured to have specific access, and then individual users can be given these roles. This saves the time and effort of setting-up separate access for each individual user. This may include a Report Reader role; which has access to reporting assets, Data Readers; who can query the database, but not modify it and Data Developers; who have some (but not complete) access to add, modify and delete data and reports.
Technical safeguards
On the technical side, there are many options to increase safeguards and lower security risks around your data that do not involve buying new software. Many of these options come down to how the data model itself is setup. In one example, an organization suffered a data breach, but lost no customer data simply because of what data they owned and how it was stored (3). Some careful considerations around your data model can have a big impact on security and compliance.
The most basic step is to make sure your data platform has a semantic layer. In short, this includes the parts of your data model that are visible to business users. Typically, this exists as data marts or views which sit on top of where the data is stored. Data elements in the semantic layer should be easily understood and difficult to misuse and abuse, by accident or with intent. Having this layer available gives information security more agency in applying processes, such as locking down specific reports or tables based on roles.
An important principle of any data modeling strategy is not to store the same information in multiple places. The impact of this is magnified in the face of regulations such as GDPR and CCPA, which require organizations to purge certain data from their systems. This can pose a significant issue to organizations who may not be aware of every place this data is stored. Much of this risk can be mitigated through pseudonymization, which is the method of replacing sensitive data fields with de-identified field, or “synonyms”. These synonyms can be re-identified with a corresponding value in a separate table, which has additional security. If that data needs to be purged, it can be done so from that one secure location, and the synonym can no longer be re-identified.
Although data breaches are sometimes the result of malicious hackers, it is important to recognize the huge amount of risk that comes from human error from users within each organization. A data governance program should consider communications and training initiatives to increase data literacy, technical training on SQL and reporting tools and audits on security measures to make sure business users cannot accidentally misuse data assets.
Get going on the 'how'
The security, privacy and compliance processes that are part of an organization’s data governance program are going to depend largely on the industry of the organization and the maturity of its data platform. Companies should work first to identify the largest risks and opportunities in this realm. Only then can they focus on the tangible steps that can be taken to guard against the many threats to data security and privacy and improve the capabilities of their data platform. Our professionals are here to help you along your data journey, contact us to get going on your 'how.'

