
Moving to a cloud data warehouse using Microsoft Azure
Implementing a data warehouse in the cloud using Microsoft Azure technologies can help companies of all sizes move to a modern cloud data platform while leveraging the value created in an existing on-premises data warehouse.
Azure Data Lake for source data organization
Benefits of a data lake
- Simple access and cost-effective storage for scalable sourcing of data over time
- Standardized format and consistency across the organization
- Format offerings include open-source options, such as Apache Parquet
- Partitioning of data in patterns can be performed in-line with big data best practices
- Access can be distributed business-wide
- Implementation early in the process allows for rapid and agile development and provides a way to reload the data model from a history of immutable data
Azure Data Lake Generation 1 and 2
While Azure Data Lake Generation 1 provides a solid solution for storing and organizing source data, Generation 2 (1) offers an improved product:
- Generation 2 can read and write faster (2) than Generation 1
- Generation 2 also stores data the same way as other Azure storage services, allowing users to access data using a variety of familiar methods
Use Azure data factory for orchestration
General architecture
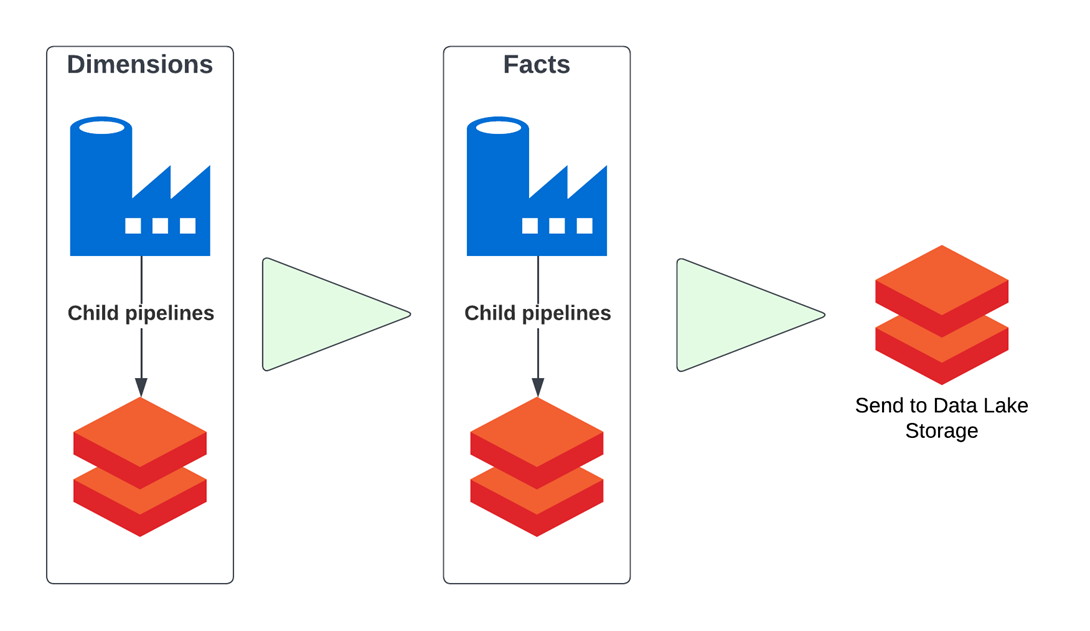
What is Azure Data Factory?
Azure Data Factory (3) is a cloud tool for orchestrating events in a logical progression using “pipelines.” It allows users to move data, call events, send notifications, look up data and even call other pipelines. This can all be done in sequence, in loops, in parallel, or dependent on actions occurring within the pipeline. For this scenario, it is important to know that Azure Data Factory allows calls to Azure Databricks with parameters.
As a basic example of an ETL platform, a user can set up a pipeline to copy data to a staging area in data lake, then run an Azure Databricks notebook to transform the data as needed and finally, send the transformed data to a separate landing zone.
Benefits of Azure Data Factory
There are several benefits of using Azure Data Factory for a cloud data warehouse:
- Integration with the Azure platform, providing a direct link to the Data Lake, Databricks, SQL Server and Synapse
- Pipeline triggers, either by schedule or a file being updated
- Parallel execution using Azure Data Factory’s powerful “for-each loop” features
- Scalability and extensibility to data sets of all sizes
- Alerts and logging sent to Azure Log Analytics for operational management
- Deployments via Azure’s DevOps platform
Orchestration only
While Data Factory’s Data Flow is available as a transform tool, the practice for this type of project has been to write standardized and custom Databricks notebooks.
This keeps the areas of concern separate, contains business logic for building in one place, allows the use of Databricks’ notebook version control for development releases and allows the organization to easily change where the final data sets are surfaced if necessary.
Process data using Azure Databricks
What is Azure Databricks?
Databricks is a cloud platform built around Apache Spark. Spark is an open-source distributed processing framework that enables fast processing of big data with multiple improvements over the original MapReduce paradigm (4). Databricks provides additional features for ease of use such as managed clusters, collaborative workspaces and a notebook-style interface. Azure Databricks (5) is the Databricks platform hosted on Azure.
Why use Databricks?
Azure Databricks is currently the technology of choice for handline data engineering on Azure.
Key resources to use Azure Databricks:
- Provides an array of cluster sizes and can automatically scale clusters up and down as needed
- Integrates with Azure Active Directory
- Supports multiple languages, including Python, R and SQL
- The runtime offers improved performance over Spark (6)
- Workspaces provide an interface for multiple users to collaboratively develop Spark applications
For a cloud-first data warehouse, Azure Databricks provides the tools and flexibility needed to integrate a variety of data types. It also provides the computational power needed to process big data without requiring data engineering teams to develop additional code for cluster management.
Persist modeled data using Delta Lake
What is Delta Lake?
Open source
- Delta Lake (7) is an open-source storage technology under the Databricks platform that comes standard with a Databricks subscription. As an open-source product, it is extensible to many solutions.
Parquet
- Files that represent the stored data use the Parquet (8) file format, providing compressed columnar storage. Parquet is also an open-source technology provided by Apache, which works well with the Apache Spark ecosystem that drives Databricks clusters.
Why use Delta Lake?
Data Lake
- Delta Lake provides storage of staged and transformed data for the model in Azure’s Data Lake.
Malleable
- It allows changes to the data in the form of deletes, updates and merges, which supports slowly changing dimensions, incremental data loading and ad-hoc data updates. The data is stored as snapshots so users can get data from a certain point in time in case an older version of the data set is needed. The retention period for snapshots is customizable (9). Data files can be optimized (10) for even better performance based on key values and partitioning.
Transactional
- Delta Lake data supports Atomicity, Consistency, Isolation, Durability (ACID) concepts. It conserves data quality, as model data and keys do not have to be rebuilt upon each run.
Efficient
- It is an efficient way of storing data, using Parquet as a format in the lake. Parquet’s storage footprint is small and can be read by Databricks very quickly compared to other formats.
How we can help
The Microsoft Azure data platform stack provides flexibility, ease of scaling and speed to deliver on the promise of the data warehouse in the cloud. Ingestion, storage and transformation of data occur using Azure Data Factory, Data Lake Storage and Databricks. Additional complementary Azure services can build on this framework to address many of the most common use cases.
The Microsoft analytics stack then provides additional capabilities on top of the data warehouse to deliver the analytics, insights and predictions that lead to data-driven decision-making.
Interested in learning more?
References
1. https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction
2. https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
3. https://azure.microsoft.com/en-us/services/data-factory
4. https://www.infoworld.com/article/3236869/what-is-apache-spark-the-big-data-platform-that-crushed-hadoop.html
5. https://www.infoworld.com/article/3236869/what-is-apache-spark-the-big-data-platform-that-crushed-hadoop.html
6. https://databricks.com/blog/2017/07/12/benchmarking-big-data-sql-platforms-in-the-cloud.html
7. https://databricks.com/product/databricks-delta
8. https://parquet.apache.org
9. https://docs.databricks.com/delta/optimizations.html
10. https://docs.databricks.com/delta/optimizations.html
