
Extracting text from unstructured data for intelligent automation
Many businesses experience a recurring challenge regarding the optimal use of unstructured text data in workflow automation and analytics reporting. Within these documents, key words and phrases play an important role in obtaining the idea behind text data quickly, eliminating the need to read the entire text document. This innovation can accelerate workflow automation and analytics reporting, and a vital part of assisting in this information retrieval domain includes leveraging machine learning and Natural Language Processing (NLP) capabilities on Amazon Web Services (AWS).
To better understand key word and phrase extraction, let’s explore an example that illustrates how key word and key phrase extraction can be used to support accounting challenges related to the ASC 842 lease accounting standard, which required a manual review of leases. The business request was to identify key lease terms, such as lease commencement, termination dates and base rent amounts, from PDF documents to accelerate the review process. The following graphics show the input, a lease in PDF format, and the output, an Excel spreadsheet, with the key terms identified in this lease.
Input:

Output:

This output Excel spreadsheet allows business leaders to streamline their review because they can focus their attention on just the list of PDF documents listed within the output report. If a business leader is attempting to sift through several thousand PDF documents, this NLP technology can reduce their manual effort and allow employees to finish their reporting projects quicker.
Additionally, NLP and key term extraction technology can also help with other types of business challenges, across industries:
Aerospace industry:
- Product performance and reliability reporting in the aerospace industry presented with challenges in identifying which component was involved in a failure, by manufacturer serial number; when the failure occurred; and which airline, aircraft and flight phase was involved, by extracting key terms from unstructured text.
- Text data needed to be processed from the call center, field customer representative notes, shipping manifests and repair shop test results on items returned for a service repair, to connect the different data sources and tell the “story of the plane” with analytics.
Manufacturing compliance:
- Compliance in the manufacturing industry required identification of the product name, company name and address, hazard identification, first aid measures, handling and storage procedures and personal protective equipment, as required by safety data sheets (SDS), to assist with a workflow automation project.
- The ability to perform key term extraction has helped reduce manual processing for improved compliance and safety within manufacturing facilities.
Fraud investigation:
- For a fraud investigation, the forensic accounting team needed to review four years of bank transactions received as PDFs, obtained from 14 different accounts from five different banks.
- Key word and key phrase extraction were required in order to identify account number, transaction date, amount, description and to process over 1.5 million individual bank transactions.
Understanding the methodology
James Taylor’s book Decision Management Systems - A Practical Guide to Using Business Rules and Predictive Analytics takes an iterative framework for labeling business decisions through decomposing operational decisions. This methodology is useful to keep teams grounded on the business metric to be improved and how to measure the improvement in relation to business value. By utilizing this approach, businesses can oftentimes discover several “hidden” micro-decisions. Typically, these micro-decisions are where the level of effort is relatively lower and the business value is higher as compared to other decision types, which makes these types of decisions prime candidates for Intelligent Automation – a machine learning approach. By identifying the strategic, tactical, operational and micro goals, needs and decisions of a business, leaders can be better prepared to streamline operations:
- Strategic decisions are high-value, low-volume decisions, made by senior or other management and made only once in that context.
- Tactical decisions are medium value and repeatable on some frequency such as weekly or monthly, made by managers or knowledge workers, and based on similar analysis each time. An example would be how much of a discount to apply to a customer order.
- Operational decisions are of lower value and relate to a single business transaction and are still important for operational effectiveness given the volume and number of times they are repeated.
- Micro-decisions are a specific subset of operational decisions. Micro-decisions use everything known about the event to make a unique decision for the transaction. They apply a layer of personalization to the decision, are by far the most common decision type, and are highly repeatable. An example of a micro-decision is identifying complete bank transactions from an unstructured, variable length, streaming data source, based on unique bank signals that delineate the start of each transaction and each data element within the transaction.
Our technical goal was to provide a solution to reduce the need for manual processing, particularly for large volumes of unstructured text. To guide clients through their digital journey, we developed five functional modules, shown below, with each module focused on a single logical task.
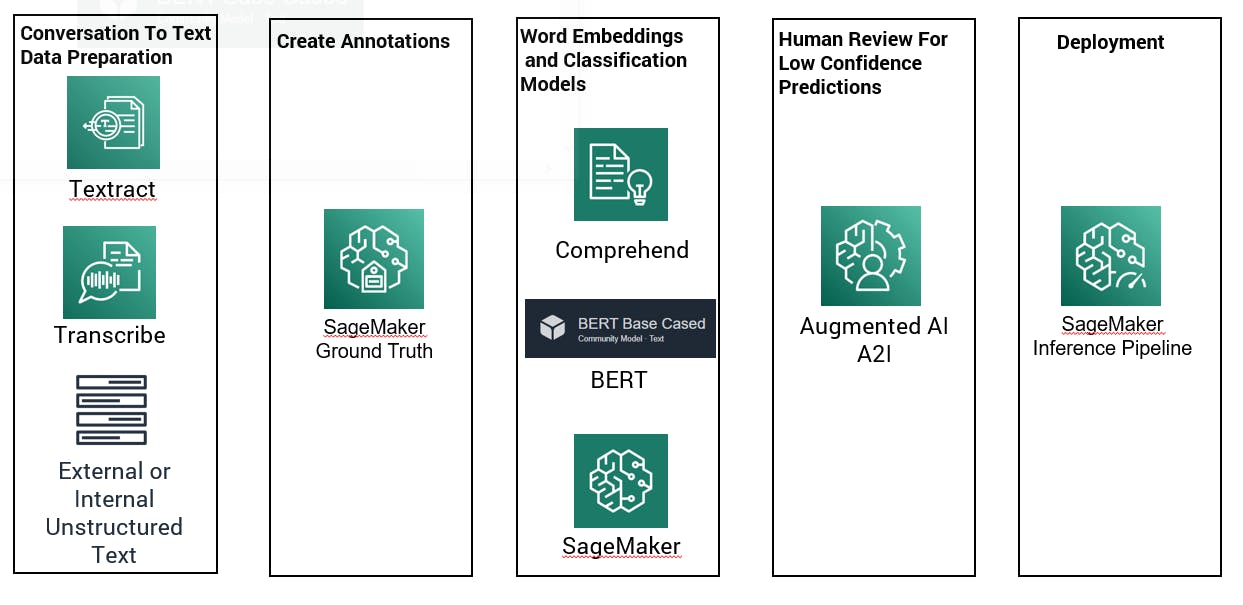
These five modules are further outlined below:
- Processing semi-structured or unstructured text from internal and external sources. AWS Textract can be used to convert PDF documents to text using optical character recognition (OCR) and AWS Transcribe can be used to convert audio recording to text.
- AWS SageMaker Data Wrangler and a Jupiter notebook can be used to perform data cleaning and feature engineering such as detecting sentence boundaries and removing punctuation.
- AWS SageMaker Ground Truth can be used during the annotation process to create labels based on the key terms required. During an initial prototype, a data quality assessment can be conducted to create initial customer classification models within AWS Comprehend to validate the approach and guide the business during the feature engineering process.
- Once the approach is validated, Bidirectional Encoder Representations from Transformers (BERT) can be used to create word embeddings. Next, classification models can be used with Linear Learner and XGBoost in SageMaker, as well as Stochastic Gradient Descent and Support Vector Machines in scikit-learn.
- Another strong model that can be deployed is REST Application Programming Interface (API) using SageMaker Inference Pipeline which supports real-time predictions and batch transformations. The inference API is integrated into common web front-end languages such as JavaScript, C# and Angular, as well as RPA low code software like UiPath, Blue Prism or Pega. The inference API can also be integrated with Redshift, AWS RDS and Athena, using a Lambda function to perform a traditional “in database” inference.
Extracting future business insights
Baker Tilly’s solution for key word and phrase extraction for unstructured text data is a valuable approach for a business’s digital transformation given it involves workflow automation and analytics reporting. By engaging in this approach, business leaders could reduce their operational risk and increase their knowledge and capabilities when it comes to automated technology – thus streamlining operations.
